
Photo by Unsplash
VHHCorpus
VHHCorpusは、アルパカから採取したVHH (Variable domain of Heavy chain of Heavy chain antibody)の全長のアミノ酸配列からなる事前学習用コーパスである。現在、200万以上のVHH配列を含むVHHCorpus-2Mを公開しています。VHHCorpus-2Mは、VHHに特異的な言語モデルの事前学習に使用できます。
列の説明
データセットの各列の内容と形式の説明です。
列名 | 説明 |
VHH_sequence | VHHのアミノ酸配列 |
subject_species | VHHが採取された対象の種 |
subject_name | VHHが採取された対象の名前 |
subject_sex | VHHが採取された対象の性別 |
パイプライン
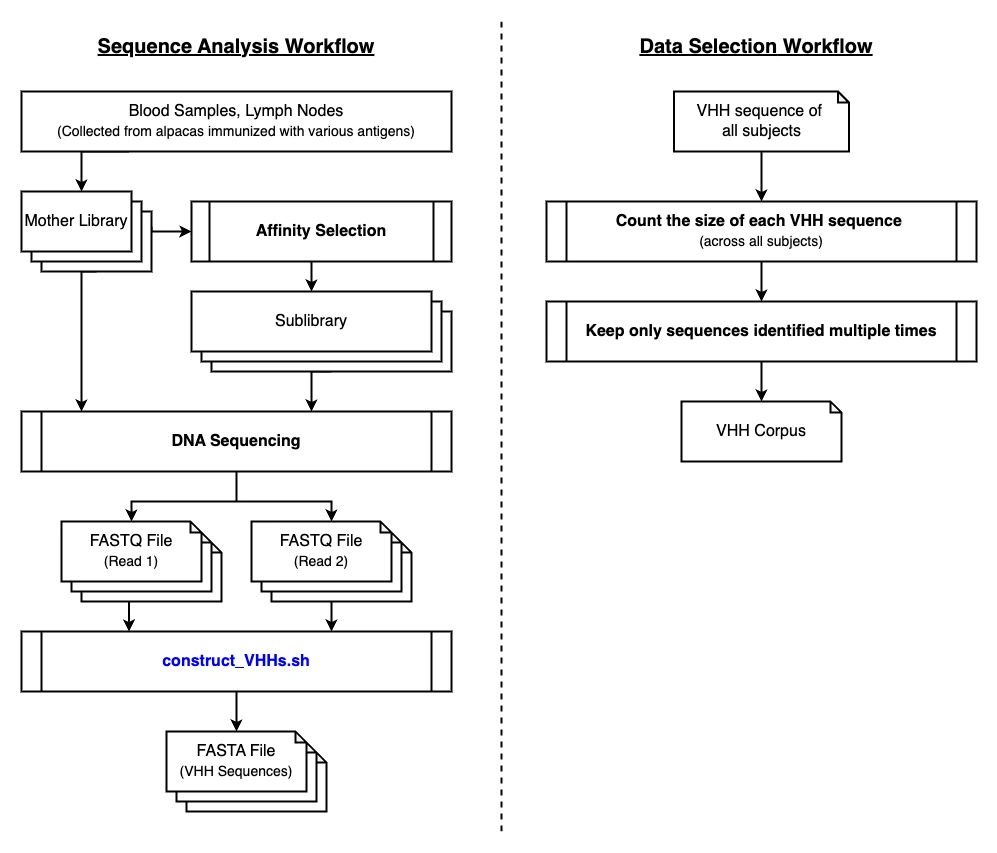
VHHCorpusは、以下のワークフローによって生成されました。青色で強調されたスクリプトは、GitHubで公開しています。
サブジェクト
VHHCorpus-2Mは、AVIDa-SARS-CoV-2の作成に使用されたアルパカとは異なる5頭のアルパカから作成されたVHH配列のコーパスです。VHHCorpus-2Mには、ラベル付き結合データセットとして公開されていない複数のデータセットと、すでに公開されているAVIDa-hIL6が含まれています。
Name | Species | Sex |
Lucky | Alpaca | Female |
Marin | Alpaca | Male |
Wizzy | Alpaca | Male |
Yodel-Suri | Alpaca | Female |
Yuki | Alpaca | Female |
ライセンス
このデータは クリエイティブ・コモンズ 表示 - 非営利 4.0 国際 ライセンスの下に提供されています。

データセットを商用目的で使用する場合は、[email protected]に連絡してください。
免責事項
- 許諾者が別途合意しない限り、許諾者は可能な範囲において、ライセンス対象物を現状有姿のまま、現在可能な限りで提供し、明示、黙示、法令上、その他に関わらずライセンス対象物について一切の表明または保証をしません。これには、権利の帰属、商品性、特定の利用目的への適合性、権利侵害の不存在、隠れた瑕疵その他の瑕疵の不存在、正確性または誤りの存在もしくは不存在を含みますが、これに限られず、既知であるか否か、発見可能であるか否かを問いません。全部または一部の無保証が認められない場合、この無保証はあなたには適用されないこともあります。
- 可能な範囲において、本パブリック・ライセンスもしくはライセンス対象物の利用によって起きうる直接、特別、間接、偶発、結果的、懲罰的その他の損失、コスト、出費または損害について、例え損失、コスト、出費、損害の可能性について許諾者が知らされていたとしても、許諾者は、あなたに対し、いかなる法理(過失を含みますがこれに限られません)その他に基づいても責任を負いません。全部または一部の責任制限が認められない場合、この制限はあなたには適用されないこともあります。
- 上記の無保証および責任制限は、可能な範囲において、全責任の完全な免責および免除に最も近いものとして解釈するものとします。
クリエイティブ・コモンズ 表示-非営利 4.0 国際 パブリック・ライセンス — 第5条 無保証および責任制限
https://creativecommons.org/licenses/by-nc/4.0/legalcode.ja